publicclassTrappingRainWater_42{ publicinttrap(int[] height){ int a = 0; int b = height.length - 1; int max = 0; int leftMax = 0; int rightMax = 0; while (a <= b) { leftMax = Math.max(leftMax, height[a]); rightMax = Math.max(rightMax, height[b]); if (leftMax < rightMax) { // leftMax is smaller than rightMax, so the (leftMax-A[a]) water can be stored max += (leftMax - height[a]); a++; } else { max += (rightMax - height[b]); b--; } } return max; } }
"pool-16-thread-7" #154 prio=5 os_prio=0 tid=0x00007ff581c8c000 nid=0x326d runnable [0x00007ff5468e7000] java.lang.Thread.State: RUNNABLE ... at org.apache.kafka.clients.NetworkClient.poll(NetworkClient.java:433) at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:232) - locked <0x00000000c2e04f90> (a org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient) at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:208) at org.apache.kafka.clients.consumer.KafkaConsumer.pollOnce(KafkaConsumer.java:1096) at org.apache.kafka.clients.consumer.KafkaConsumer.poll(KafkaConsumer.java:1043) at org.springframework.kafka.listener.KafkaMessageListenerContainer$ListenerConsumer.run(KafkaMessageListenerContainer.java:571) ...
// if data is available already, return it immediately Map<TopicPartition, List<ConsumerRecord<K, V>>> records = fetcher.fetchedRecords(); if (!records.isEmpty()) return records;
// send any new fetches (won't resend pending fetches) fetcher.sendFetches(); ... return fetcher.fetchedRecords(); }
The maximum amount of data per-partition the server will return. Records are fetched in batches by the consumer. If the first record batch in the first non-empty partition of the fetch is larger than this limit, the batch will still be returned to ensure that the consumer can make progress. The maximum record batch size accepted by the broker is defined via message.max.bytes (broker config) or max.message.bytes (topic config). See “ + FETCH_MAX_BYTES_CONFIG + “ for limiting the consumer request size.
@Override publicvoidrun(){ try { log.debug("Heartbeat thread for group {} started", groupId); while (true) { synchronized (AbstractCoordinator.this) { ... client.pollNoWakeup(); long now = time.milliseconds(); if (coordinatorUnknown()) { ... } elseif (heartbeat.sessionTimeoutExpired(now)) { // the session timeout has expired without seeing a successful heartbeat, so we should // probably make sure the coordinator is still healthy. coordinatorDead(); } elseif (heartbeat.pollTimeoutExpired(now)) { // the poll timeout has expired, which means that the foreground thread has stalled // in between calls to poll(), so we explicitly leave the group. maybeLeaveGroup(); } elseif (!heartbeat.shouldHeartbeat(now)) { // poll again after waiting for the retry backoff in case the heartbeat failed or the // coordinator disconnected AbstractCoordinator.this.wait(retryBackoffMs); } else { heartbeat.sentHeartbeat(now); ... } } // end synchronized } // end while } //end try } // end run
其中最重要的两个 timeout 函数:
1 2 3 4 5 6 7
publicbooleansessionTimeoutExpired(long now){ return now - Math.max(lastSessionReset, lastHeartbeatReceive) > sessionTimeout; }
publicbooleanpollTimeoutExpired(long now){ return now - lastPoll > maxPollInterval; }
sessionTimeout
如果是 sessionTimeout 则 Mark the current coordinator as dead,此时 会将 consumer 踢掉,重新分配 partition 和 consumer 的对应关系。
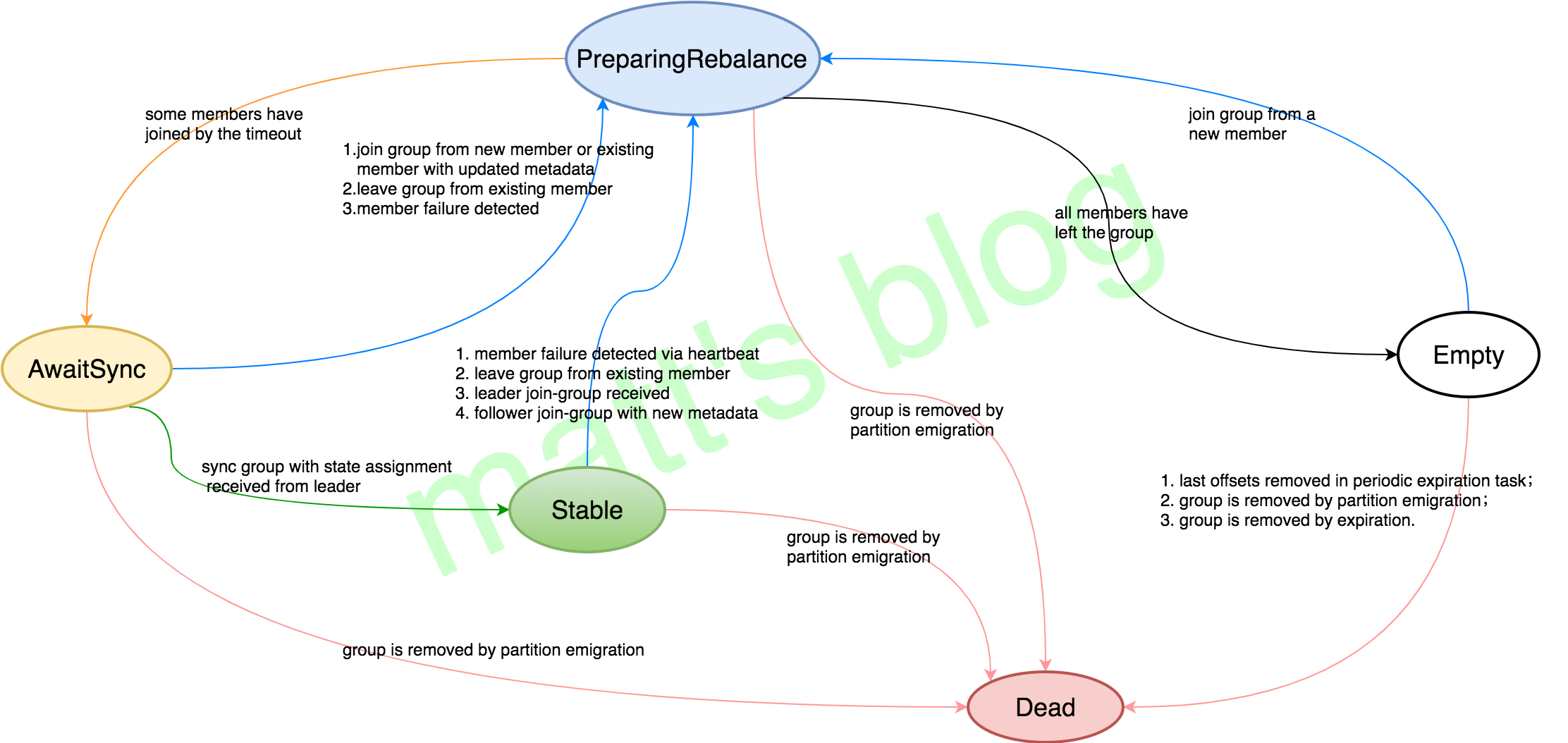
在 Kafka Server 端,Consumer 的 Group 定义了五个状态::
pollTimeout
如果是 pollTimeout 则 Reset the generation and memberId because we have fallen out of the group,此时 consumer 会退出 group,当再次 poll 时又会 rejoin group 触发 rebalance group。
This config sets the maximum delay between client calls to poll().
When the timeout expires, the consumer will stop sending heartbeats and send an explicit LeaveGroup request.
As soon as the consumer resumes processing with another call to poll(), the consumer will rejoin the group.
By increasing the interval between expected polls, you can give the consumer more time to handle a batch of records returned frompoll(long). The drawback is that increasing this value may delay a group rebalance since the consumer will only join the rebalance inside the call to poll. You can use this setting to bound the time to finish a rebalance, but you risk slower progress if the consumer cannot actually call poll often enough.
参数设置大一点可以增加两次 poll 之间处理消息的时间。 当 consumer 一切正常(也就是保持着 heartbeat ),且参数的值小于消息处理的时长,会导致 consumer leave group 然后又 rejoin group,触发无谓的 group balance,出现 consumer livelock 现象。
但如果设置的太大,会延迟 group rebalance,因为消费者只会在调用 poll 时加入rebalance。
max.poll.records
Use this setting to limit the total records returned from a single call to poll. This can make it easier to predict the maximum that must be handled within each poll interval. By tuning this value, you may be able to reduce the poll interval, which will reduce the impact of group rebalancing.
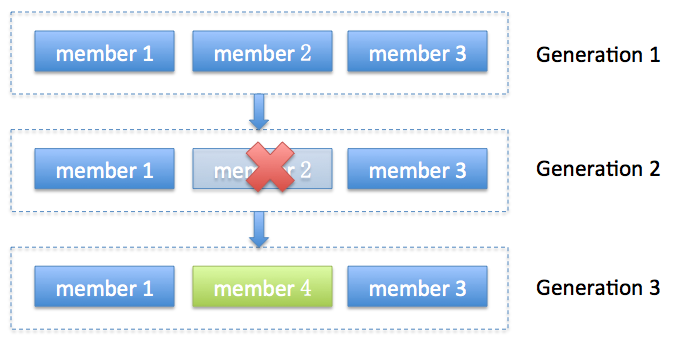
After subscribing to a set of topics, the consumer will automatically join the group when poll(long) is invoked. The poll API is designed to ensure consumer liveness. As long as you continue to call poll, the consumer will stay in the group and continue to receive messages from the partitions it was assigned. Underneath the covers, the consumer sends periodic heartbeats to the server. If the consumer crashes or is unable to send heartbeats for a duration of session.timeout.ms, then the consumer will be considered dead and its partitions will be reassigned. It is also possible that the consumer could encounter a “livelock” situation where it is continuing to send heartbeats, but no progress is being made. To prevent the consumer from holding onto its partitions indefinitely in this case, we provide a liveness detection mechanism using the max.poll.interval.ms setting. Basically if you don’t call poll at least as frequently as the configured max interval, then the client will proactively leave the group so that another consumer can take over its partitions. When this happens, you may see an offset commit failure (as indicated by a CommitFailedException thrown from a call to commitSync()). This is a safety mechanism which guarantees that only active members of the group are able to commit offsets. So to stay in the group, you must continue to call poll.
"pool-16-thread-14" #167 prio=5 os_prio=0 tid=0x00007f5b19dbf000 nid=0x7ac2 runnable [0x00007f5ae4ccb000] java.lang.Thread.State: RUNNABLE at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method) at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:269) at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:79) at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86) - locked <0x00000000c2e816b0> (a sun.nio.ch.Util$2) - locked <0x00000000c2e816a0> (a java.util.Collections$UnmodifiableSet) - locked <0x00000000c2e742a0> (a sun.nio.ch.EPollSelectorImpl) at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:97) at org.apache.kafka.common.network.Selector.select(Selector.java:529) at org.apache.kafka.common.network.Selector.poll(Selector.java:321) at org.apache.kafka.clients.NetworkClient.poll(NetworkClient.java:433) at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:232) - locked <0x00000000c2f00da0> (a org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient) at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:208) at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:168) at org.apache.kafka.clients.consumer.internals.AbstractCoordinator.joinGroupIfNeeded(AbstractCoordinator.java:364) at org.apache.kafka.clients.consumer.internals.AbstractCoordinator.ensureActiveGroup(AbstractCoordinator.java:316) at org.apache.kafka.clients.consumer.internals.ConsumerCoordinator.poll(ConsumerCoordinator.java:297) at org.apache.kafka.clients.consumer.KafkaConsumer.pollOnce(KafkaConsumer.java:1078) at org.apache.kafka.clients.consumer.KafkaConsumer.poll(KafkaConsumer.java:1043) at org.springframework.kafka.listener.KafkaMessageListenerContainer$ListenerConsumer.run(KafkaMessageListenerContainer.java:571) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745)
@Override publicbooleanneedRejoin(){ if (!subscriptions.partitionsAutoAssigned()) returnfalse;
// we need to rejoin if we performed the assignment and metadata has changed if (assignmentSnapshot != null && !assignmentSnapshot.equals(metadataSnapshot)) returntrue;
// we need to join if our subscription has changed since the last join if (joinedSubscription != null && !joinedSubscription.equals(subscriptions.subscription())) returntrue;
@Override publicvoidrun(){ try { log.debug("Heartbeat thread for group {} started", groupId); while (true) { synchronized (AbstractCoordinator.this) { ... client.pollNoWakeup(); long now = time.milliseconds(); if (coordinatorUnknown()) { ... } elseif (heartbeat.sessionTimeoutExpired(now)) { // the session timeout has expired without seeing a successful heartbeat, so we should // probably make sure the coordinator is still healthy. coordinatorDead(); } elseif (heartbeat.pollTimeoutExpired(now)) { // the poll timeout has expired, which means that the foreground thread has stalled // in between calls to poll(), so we explicitly leave the group. maybeLeaveGroup(); } elseif (!heartbeat.shouldHeartbeat(now)) { // poll again after waiting for the retry backoff in case the heartbeat failed or the // coordinator disconnected AbstractCoordinator.this.wait(retryBackoffMs); } else { heartbeat.sentHeartbeat(now); ... } } // end synchronized } // end while } //end try } // end run
其中最重要的两个 timeout 函数:
1 2 3 4 5 6 7
publicbooleansessionTimeoutExpired(long now){ return now - Math.max(lastSessionReset, lastHeartbeatReceive) > sessionTimeout; }
publicbooleanpollTimeoutExpired(long now){ return now - lastPoll > maxPollInterval; }
$x^{(j)}_i$: The value of feature j in the ith training example
例如,当 n=4 时:
For convenience of notation, $x_0$ = 1, 所以最后的特征向量的维度是 n+1,从 0 开始,记为”X”, 则有:
$θ^T$: [1 * (n+1)] matrix
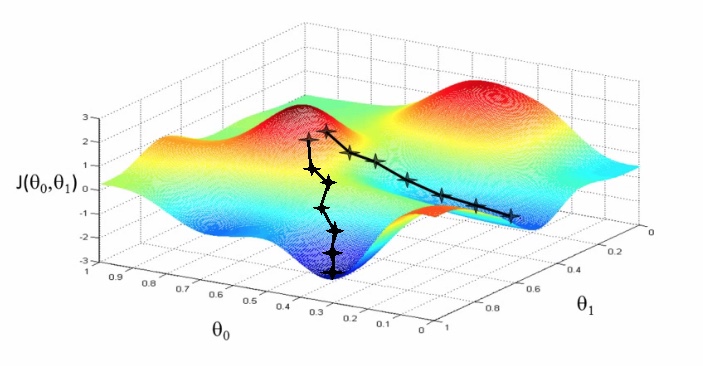
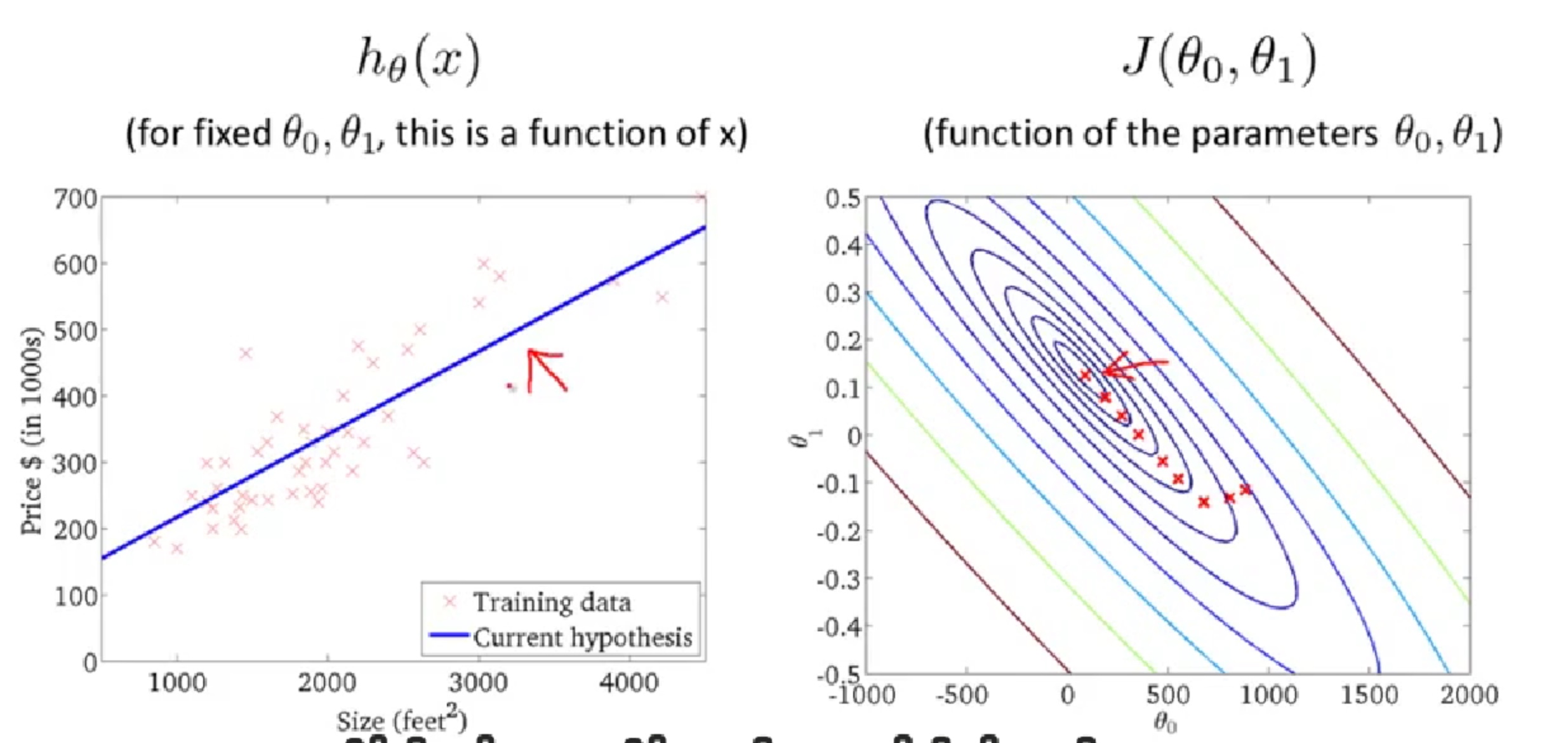
多变量的梯度下降
Cost Function
Gradient descent
Repeat {
}
every iterator
θj = θj - learning rate (α) times the partial derivative of J(θ) with respect to θJ(…)
We do this through a simultaneous update of every θj value
Gradient Decent in practice
Feature Scaling
假设只有 $x_1$,$x_2$ 两个变量,其中:$x_1\in(0,2000), x_2\in(1,5)$,则最后的 J(θ) 图形是一个椭圆,在椭圆下用梯度下降法会比圆形要耗时更久,So we need to rescale this input so it’s more effective,有很多方式,一种是将各个 feature 除以其本身的最大值,缩小范围至[0,1],一种是各个 feature 减去 mean 然后除以最大值,缩小范围至[-0.5,0.5]
Learning Rate α
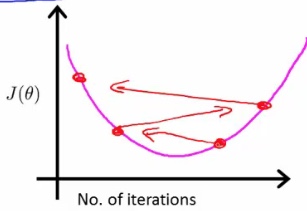
working correctly: If gradient descent is working then J(θ) should decrease after every iteration
convergence: 收敛是指每经过一次迭代,J(θ)的值都变化甚小。
choose α
When to use a smaller α
If J(θ) is increasing, see below picture
If J(θ) looks like a series of waves, decreasing and increasing again
But if α is too small then rate is too slow
Try a range of α values
Plot J(θ) vs number of iterations for each version of alpha
Go for roughly threefold increases: 0.001, 0.003, 0.01, 0.03. 0.1, 0.3
Features and polynomial regression
Can create new features
如何选择 features 和表达式尤为关键,例如房价与房子的长,房子的宽组成的表达式就会麻烦很多,若将房子的长乘以房子的宽得出面积,则有房价与房子面积的表达式,将会更容易拟合出房价的走势。
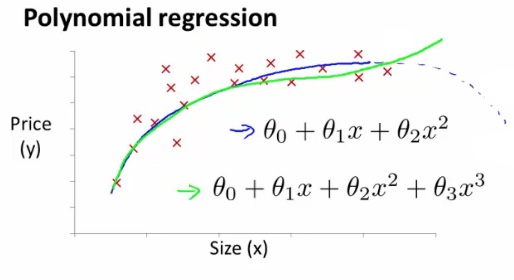
Polynomial regression
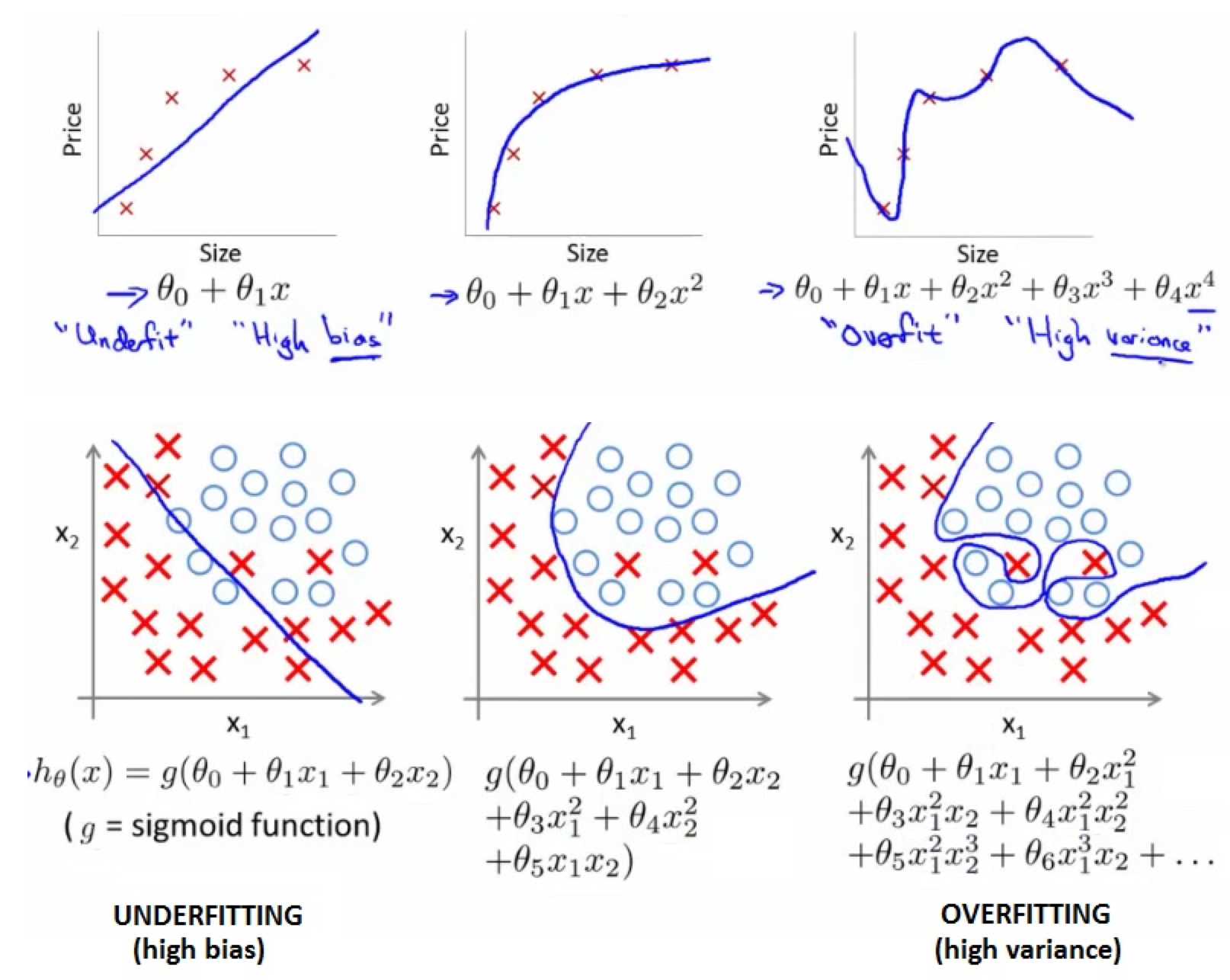
例如房价的走势,如下图,横坐标 x 为房子的面积,纵坐标为房价,使用一元二次的方程,会得出下图的蓝色曲线。容易得到房价今后会有一个下降的过程,可实际上房价是不会随着面积的增大而下降的。所以需要重新选定 Polynomial regression,可以改为使用一元三次的方程或者使用平凡根的方程。
所以选择合适的 Features 和 Polynomial regression 都非常重要。
Normal equation 求解多变量线性回归
Normal equation
举例说明,假设 J(θ) 是一元二次方程,如:J(θ)=a$θ^2$+bθ+c,则令 即可,求出最终的 θ 则得到了线性回归方程,可以预测出今后的 y 值。
更普遍地,当 θ 是一个 n+1 维的向量时,θ $\in$ $R^{n+1}$,则 cost function 如下:
只需要令:
Gradient descent Vs Normal equation
Gradient descent
Need to chose learning rate
Needs many iterations - could make it slower
Works well even when n is massive (millions)
Better suited to big data
What is a big n though: 100 or even a 1000 is still (relativity) small, If n is 10000 then look at using gradient descent
适用于线性回归会逻辑回归
Normal equation
No need to chose a learning rate
No need to iterate, check for convergence etc.
Normal equation needs to compute $(X^TX)^{-1}$
This is the inverse of an n x n matrix
With most implementations computing a matrix inverse grows by O(n3), So not great
Slow of n is large, Can be much slower
仅适用于线性回归
局部加权线性回归
局部加权回归(locally weighted regression)简称 loess,其思想是,针对对某训练数据的每一个点,选取这个点及其临近的一批点做线性回归;同时也需要考虑整个训练数据,考虑的原则是距离该区域越近的点贡献越大,反之则贡献越小,这也正说明局部的思想。其 cost function 为:
@JsonCreator publicstatic Region getRegion(String value){ for (Region region : Region.values()) { if (region.name().equals(value)) { return region; } }
return Region.GZ; }
直接将 {"region": null} 反序列化为 Region 是可行的,会调用 JsonCreator,但是如果是反序列化 Person 则不会调用到 JsonCreator,为什么呢?
publicclassRegionDeserializerextendsJsonDeserializer<Region> { @Override public Region deserialize(JsonParser jsonParser, DeserializationContext deserializationContext) throws IOException { JsonNode node = jsonParser.getCodec().readTree(jsonParser); Region region = Region.GZ;
try { if (StringUtils.isNotEmpty(node.textValue())) { return Region.getRegion(node.textValue()); } } catch (Exception e) { type = Region.GZ; }
return region; }
@Override public Region getNullValue(DeserializationContext ctxt){ return Region.GZ; } }
Person 类改为:
1 2 3 4 5 6 7
publicclassPerson{ private String name; // Address is a enum: {CH, US, GZ} @JsonDeserialize(using = RegionDeserializer.class) private Region region = Region.GZ; }
@Data @AllArgsConstructor @NoArgsConstructor @JsonIgnoreProperties(ignoreUnknown = true) publicclassPerson{ private String name; private String address = "beijing"; // default value if json missing the age field }