要解决的问题
一句话概述:
预测进入 App 首页的用户是否会点击「XLJH推荐模块」,该模块是 App 的一个功能,用户点击按钮则会进入一个XLJH的页面。
目前每天进入 App 首页的用户中,有 2.1234% 的用户会点击「XLJH推荐模块」,转化率非常低,而首页每日的曝光量是最大的,所以优化这个模块的转化率就变得尤为重要,也是本次作业要解决的问题。
整体思路
获取某一段时间的相关埋点事件、用户业务数据、用户画像等数据,将数据合并、清洗、整理为可用的数据集,然后跑决策树,随机森林和 Adaboost 三个模型。
要获取的数据是:
- 用户被展示到该模块的埋点事件
- 用户点击该模块的埋点事件
- 用户使用过 XLJH 的统计数据
- 用户画像
- 用户的业务画像
特征选取
特征举例
特征的总数非常多,总共有 280 个,抽取一些特征描述如下:
- 年龄
- 性别
- 身高
- 体重
- 业务特征 1
- 业务特征 2
- 业务特征 3
- … …
- 业务特征 n-1
- 业务特征 n
- 进入首页时距离上一次使用模块的时间
- 设备机型
获取数据
通过在 hive 里跑 sql(具体的 sql 语句略) 获取到的数据量为:54w。(单位为数据行数,下同)
特征工程
删除无用特征
- 无用特征的删除:例如 userId 等。这些特征明显与结果无关。
- 删除由预测结果导致的特征:例如使用过该模块的时间。这些特征是在预测值为 True 时才会有值,而且这特征的赋值在要预测的事件发生之后。
特征的空值处理
- 删除特征为空的数据,例如年龄,性别等必须会有的特征。
- int 类型的特征将空值填充为 0,例如某业务的 累计分钟数,某实体数量,粉丝数量,过去7天的XX业务使用统计等
- string 类型的特征将空值填充为 0,例如 citycode,tags 等。
处理重要特征
跑完 Random Forest 模型,可以输出 Feature importances 列表, Top 10 的图略。
其中需要特别处理的特征是 c.bmi 和 c.age。
分析数据后发现年龄为空值的情况非常少,所以把 c.age 为空的数据删掉。
c.bmi 需要用户填入身高和体重,这部分数据缺失一些,所以填为 c.bmi 这一列的平均值,数据集中的 dataset[c.bmi].mean = 23.3174390247965,符合常识。
特征标签化
数据标准化的处理方式如下:
1 | from sklearn import preprocessing |
可用数据量
按如上方式处理完后,最终可用的数据量为:30w
模型调优
Decision Tree 调优
树的深度调优
使用的特征数量为 275 个,使用的训练集数量为 54801。
不同树深度对应的模型评估如下:
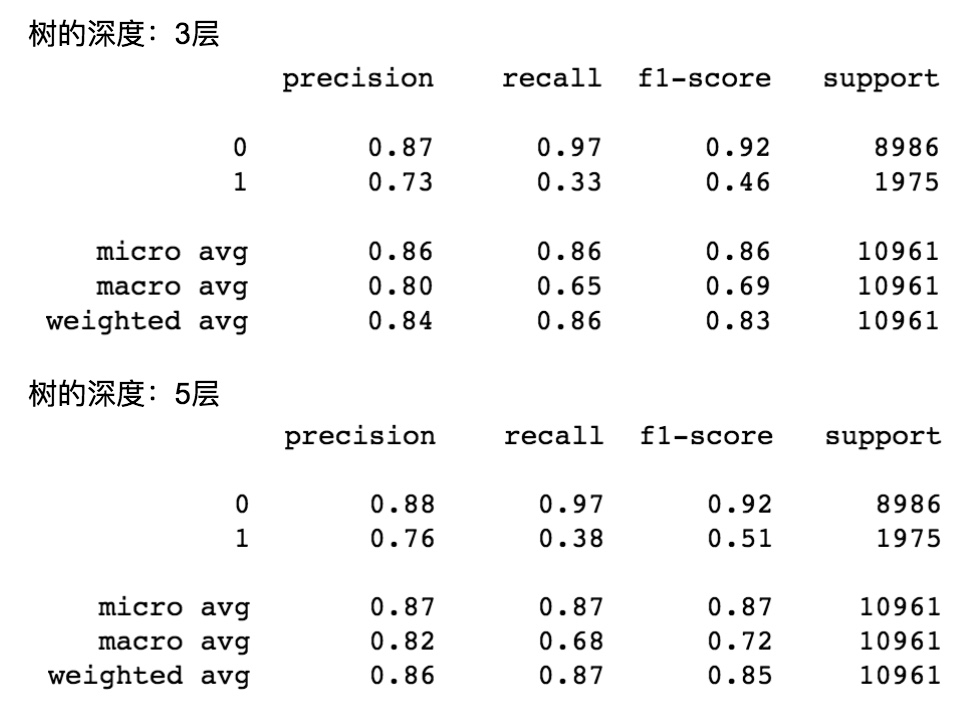
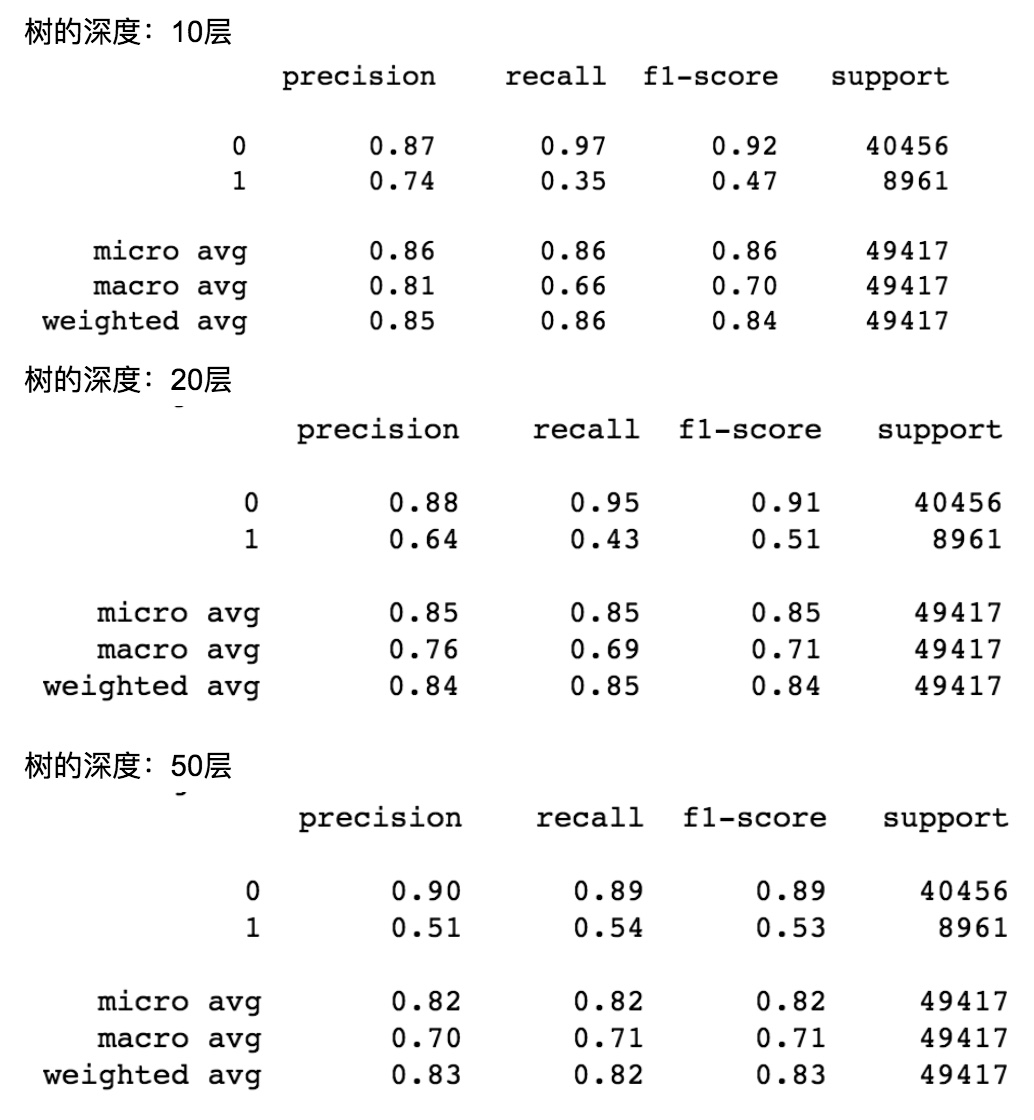
可以发现树的深度越高,召回率越高,准确率却越低。总体评价是树的深度为 5 最好。
其他参数调优
max_features=’sqrt’ 加了这个反而变差了很多。
min_samples_split=5, min_samples_leaf=5,加了这个反而变差了一些。
DT 输出
深度为 5 的 DT 截取部分放大后的图如下: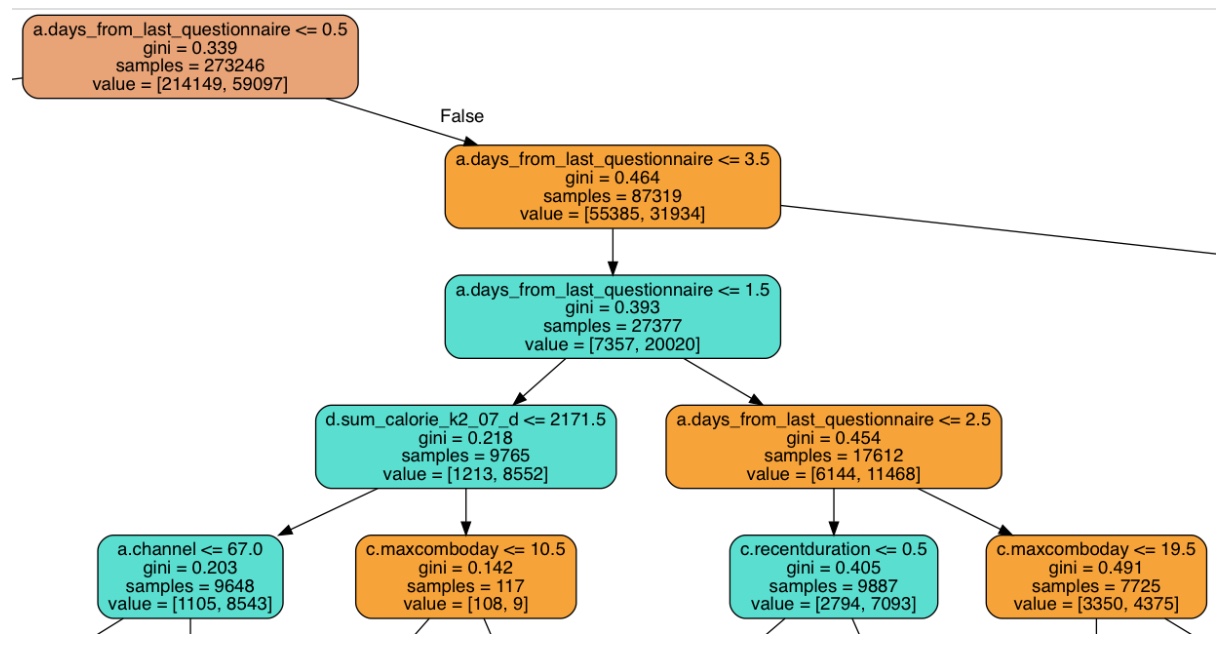
Random Forest 调优
n_estimators:100, 300, 500 都试过,差别不大。弱学习器的最大迭代次数太小会不准确,太大模型训练地就很慢。
oob_score: True,即采用袋外样本来评估模型的好坏,提高模型拟合后的泛化能力。
基本上,RF 不怎么需要调参。
比较有价值的是能产生特征的重要性,Top 30 Feature importances 的图片略。
Feature importances Top 10 的可视化略。
使用 GridSearchCV 搜索最优参数,参数搜索结果如下:
但是使用参数后,RF 的 AUC 降到了 0.82,应该是 max_features 和 min_samples_leaf 这两个参数调的不对。
Adaboost 调优
AdaBoostClassifier 的 base_estimator 选择已经之前训练好的 DT,效果更好,如下:
1 | adb_clf = AdaBoostClassifier(n_estimators=100, random_state=100, learning_rate=0.02).fit(X_train, y_train) |
learning_rate 设置为 0.02 能兼顾速度和效果。
踩过的坑
信息熵
基尼指数和信息熵的几乎无差别,不怎么影响结果。
PCA 降维
PCA 降维,使用 mle 和 5 个特征,都不好使,准确度反而更低,AUC 得分降至 0.51。
用了未来特征
决策树 AUC: 0.52 -> 0.77
随机森林 AUC: 0.82->0.93
随机森林的模型评价如下: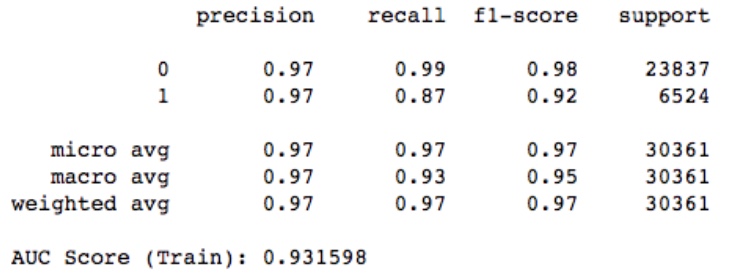
会发现准确度太高了,仔细分析后,发现用了一个「创建体测时间」的特征,而这个特征是在用户点击了 「智能计划推荐模块」后会更新值的,所以相当于用了事件发生后的特征来预测事件发生的概率,这样肯定会导致模型的准确率很高。后来去掉了这个特征。
模型对比
数据集:30w,其中正样本的比例为 22%。
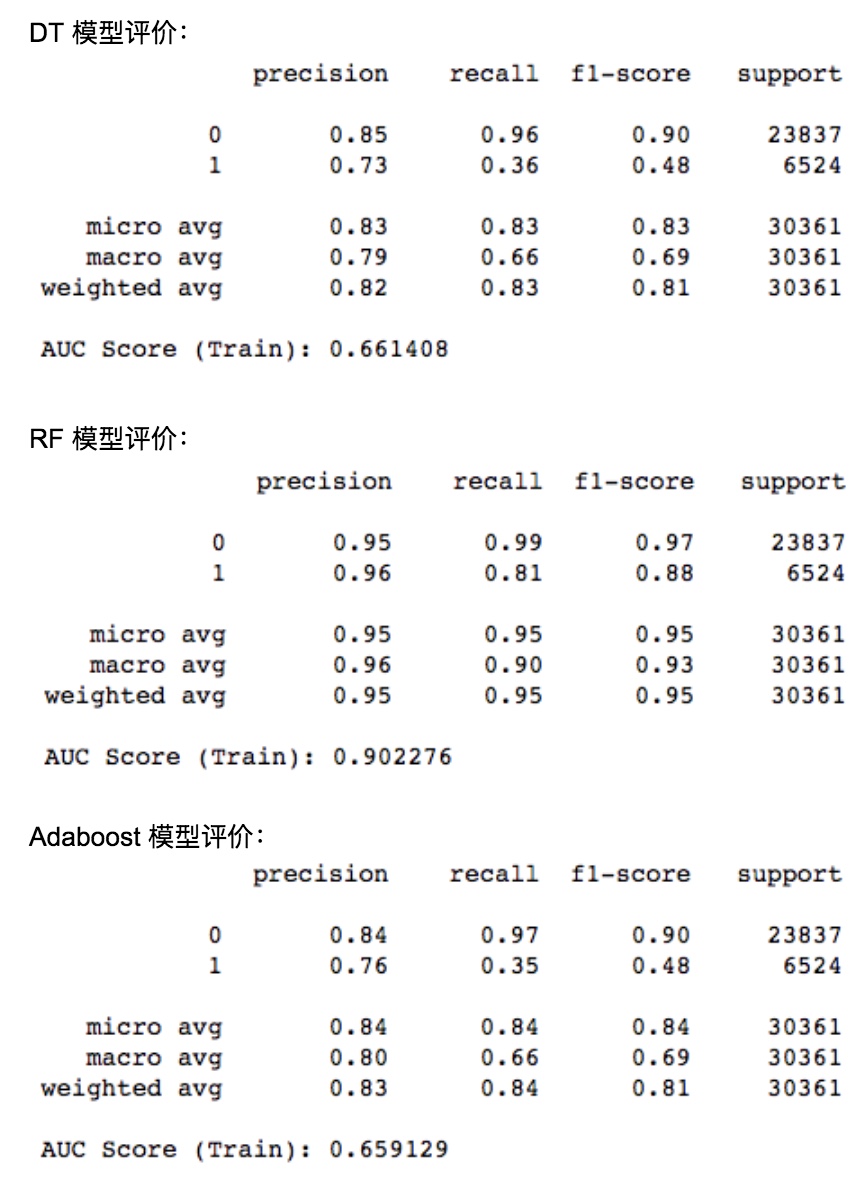
对比发现,DT 和 Adaboost 的效果都不好,AUC Score 都在 0.65 左右。RF 的效果最好,AUC Score 能到 0.90。
可能是因为数据集符合 low bias, high variance 的规律,所以 RF 要比 Adaboost 好。
RF 的准确率和召回率都还不错,感觉可以后续上线用于 App 首页了。
总结
整个过程可以抽象为:
获取数据 -> 调整模型参数 -> 引入更多特征 -> 调整模型参数 -> PCA -> 减少特征 -> 处理重要特征 -> gridSearchCV -> 调整模型参数
一些总结:
- 特征工程很重要,特征处理好后 AUC 有明显的提升
- 调参也有用,但相比起来,好的特征更有用
- 基尼系数和熵的区别不大
- 树的层数越多,准确率越低,召回越高
- AdaBoostClassifier base_estimators 用训练好的决策树来做,效果更好
- gridSearchCV 搜索最有用的参数太慢了,而且最终效果还不好
- 小心引入未来特征!
参考文档
决策树分类器在Scikit-learn的使用小结 - qq_29003925的博客 - CSDN博客
sklearn中的回归决策树 - FontTian的专栏 - CSDN博客
1.10. 决策树 — scikit-learn 0.19.0 中文文档 - ApacheCN
pandas的汇总和计算描述统计 - 修炼之路 - CSDN博客
数据分析-pandas数据处理清洗常用总结 - 简书
https://www.zhihu.com/question/29316149/answer/252391239
集成学习概述(Bagging,RF,GBDT,Adaboost) - U R MINE - CSDN博客
数据预处理与特征选择 - Joe的博客 - CSDN博客
谈谈评价指标中的宏平均和微平均 - robert_ai - 博客园
https://blog.csdn.net/sinat_26917383/article/details/75199996
DecisionTreeClassifier和DecisionTreeClassifier 重要参数调参注意点 - akon_wang_hkbu的博客 - CSDN博客
机器学习-分类器-Adaboost原理 - 宋兴柱 - 博客园
