1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
| from sklearn.datasets import fetch_20newsgroups
from pprint import pprint
from sklearn.feature_extraction.text import TfidfVectorizer
fetch_20newsgroups(data_home='/Users/ljp/Codes/ivy_plan/naive_bayes/20_newsgroups',
subset='train',
categories=None,
shuffle=True,
random_state=42,
remove=(),
download_if_missing=True
)
newsgroups_train = fetch_20newsgroups(subset='train')
vectorizer = TfidfVectorizer()
vectors = vectorizer.fit_transform(newsgroups_train.data)
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score,f1_score
clf=MultinomialNB(alpha=0.1)
clf.fit(vectors,newsgroups_train.target)
newsgroups_test=fetch_20newsgroups(subset='test')
vectors_test=vectorizer.transform(newsgroups_test.data)
from sklearn.metrics import classification_report
pred=clf.predict(vectors_test)
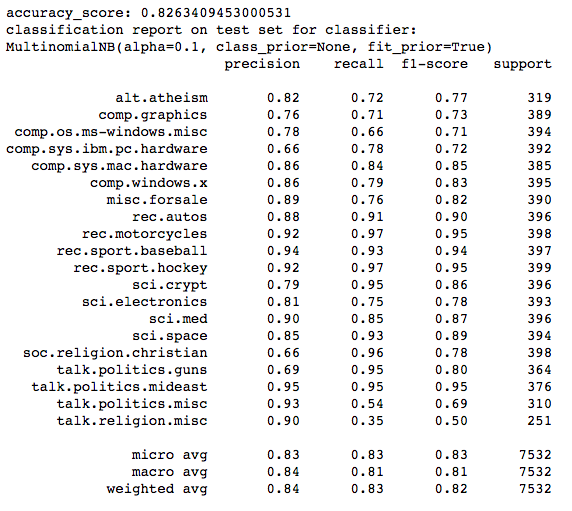
print('accuracy_score: ' + str(accuracy_score(newsgroups_test.target,pred)))
print("classification report on test set for classifier:")
print(clf)
X_test = vectorizer.transform((d for d in newsgroups_test.data))
pred = clf.predict(X_test)
y_test = newsgroups_test.target
print(classification_report(y_test, pred, target_names=newsgroups_test.target_names))
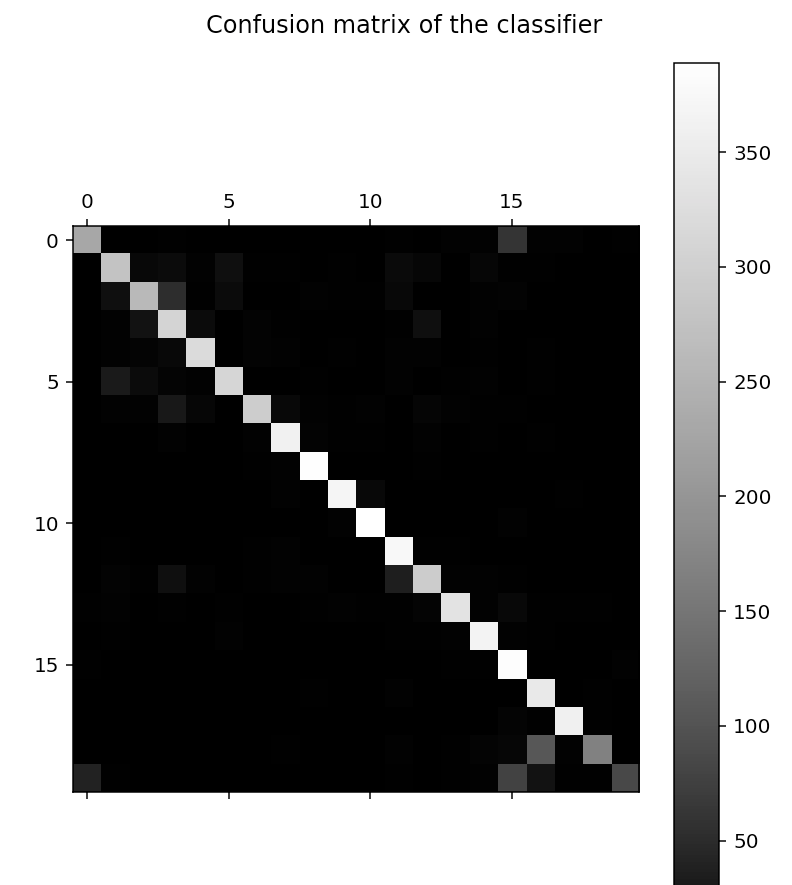
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, pred)
print("confusion matrix:")
print(cm)
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 8), dpi=144)
plt.title('Confusion matrix of the classifier')
ax = plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.spines['bottom'].set_color('none')
ax.spines['left'].set_color('none')
ax.xaxis.set_ticks_position('none')
ax.yaxis.set_ticks_position('none')
ax.set_xticklabels([])
ax.set_yticklabels([])
plt.matshow(cm, fignum=1, cmap='gray')
plt.colorbar()
plt.show()
|