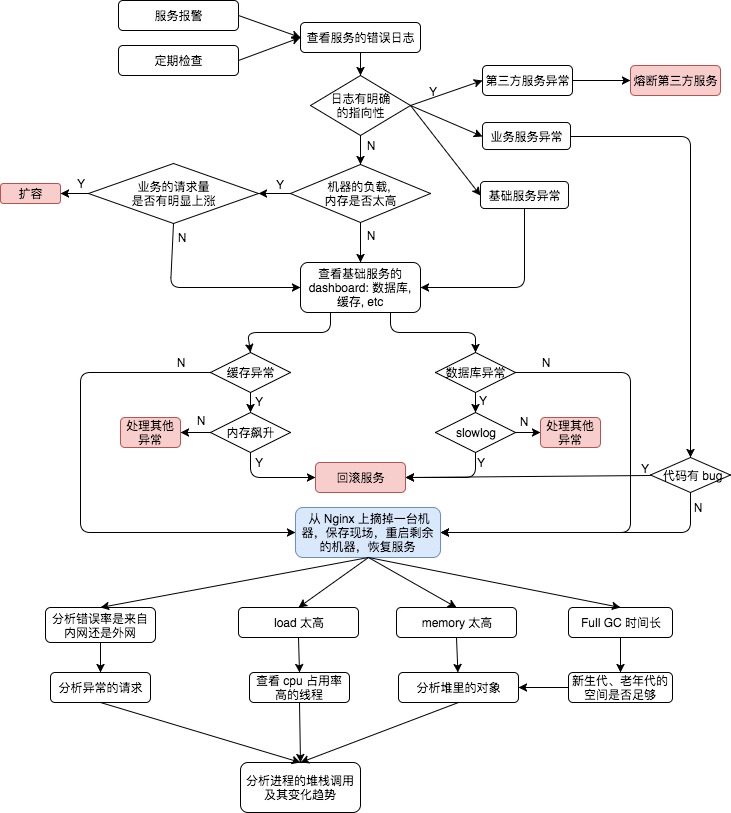
服务异常的处理流程
负载
查看机器 cpu 的负载
1 | top -b -n 1 |grep java|awk '{print "VIRT:"$5,"RES:"$6,"cpu:"$9"%","mem:"$10"%"}' |
查找 cpu 占用率高的线程
top -p 25603 -H
printf 0x%x 25842
jstack 25603 | grep 0x64f2
cat /proc/interrupts
(1)CPU
(2)Memory
(3)IO
(4)Network
可以从以下几个方面监控CPU的信息:
(1)中断;
(2)上下文切换;
(3)可运行队列;
(4)CPU 利用率。
内存
系统内存
free 命令
[root@server ~]# free
1 | total used free shared buffers cached |
这里的默认显示单位是kb。
各项指标解释
- total:总计物理内存的大小。
- used:已使用多大。
- free:可用有多少。
- Shared:多个进程共享的内存总额。
- buffers: 磁盘缓存的大小。
- cache:磁盘缓存的大小。
- -/+ buffers/cached): used:已使用多大,free:可用有多少。
- 已用内存 = 系统used memory - buffers - cached
(47000 = 3250000-201000-3002000) - 可用内存 = 系统free memory + buffers + cached
(3213000 = 10000+201000+3002000)
什么是buffer/cache?
- buffer 指 Linux 内存的:Buffer cache,缓冲区缓
- cache 指 Linux内存中的:Page cache,页面缓存
page cache
page cache 主要用来作为文件系统上的文件数据的缓存来用,尤其是针对当进程对文件有 read/write 操作的时候。如果你仔细想想的话,作为可以映射文件到内存的系统调用:mmap是不是很自然的也应该用到 page cache?在当前的系统实现里,page cache 也被作为其它文件类型的缓存设备来用,所以事实上 page cache 也负责了大部分的块设备文件的缓存工作。
buffer cache
buffer cache 主要用来在系统对块设备进行读写的时候,对块进行数据缓存的系统来使用。这意味着某些对块的操作会使用 buffer cache 进行缓存,比如我们在格式化文件系统的时候。一般情况下两个缓存系统是一起配合使用的,比如当我们对一个文件进行写操作的时候,page cache 的内容会被改变,而 buffer cache 则可以用来将 page 标记为不同的缓冲区,并记录是哪一个缓冲区被修改了。这样,内核在后续执行脏数据的回写(writeback)时,就不用将整个 page 写回,而只需要写回修改的部分即可。
在当前的内核中,page cache 是针对内存页的缓存,说白了就是,如果有内存是以page进行分配管理的,都可以使用page cache作为其缓存来管理使用。
当然,不是所有的内存都是以页(page)进行管理的,也有很多是针对块(block)进行管理的,这部分内存使用如果要用到 cache 功能,则都集中到buffer cache中来使用。(从这个角度出发,是不是buffer cache改名叫做block cache更好?)然而,也不是所有块(block)都有固定长度,系统上块的长度主要是根据所使用的块设备决定的,而页长度在X86上无论是32位还是64位都是4k。
系统如何回收cache?
Linux内核会在内存将要耗尽的时候,触发内存回收的工作,以便释放出内存给急需内存的进程使用。一般情况下,这个操作中主要的内存释放都来自于对buffer/cache的释放。尤其是被使用更多的cache空间。既然它主要用来做缓存,只是在内存够用的时候加快进程对文件的读写速度,那么在内存压力较大的情况下,当然有必要清空释放cache,作为free空间分给相关进程使用。所以一般情况下,我们认为buffer/cache空间可以被释放,这个理解是正确的。
但是这种清缓存的工作也并不是没有成本。理解cache是干什么的就可以明白清缓存必须保证cache中的数据跟对应文件中的数据一致,才能对cache进行释放。所以伴随着cache清除的行为的,一般都是系统IO飙高。因为内核要对比cache中的数据和对应硬盘文件上的数据是否一致,如果不一致需要写回,之后才能回收。
在系统中除了内存将被耗尽的时候可以清缓存以外,我们还可以人工触发缓存清除的操作。
进程内存
进程内存统计
/proc/[pid]/status
通过/proc/
cat /proc/[pid]/status1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17Name: gedit /*进程的程序名*/
State: S (sleeping) /*进程的状态信息,具体参见https://blog.chinaunix.net/u2/73528/showart_1106510.html*/
Tgid: 9744 /*线程组号*/
Pid: 9744 /*进程pid*/
PPid: 7672 /*父进程的pid*/
TracerPid: 0 /*跟踪进程的pid*/
VmPeak: 60184 kB /*进程地址空间的大小*/
VmSize: 60180 kB /*进程虚拟地址空间的大小reserved_vm:进程在预留或特殊的内存间的物理页*/
VmLck: 0 kB /*进程已经锁住的物理内存的大小.锁住的物理内存不能交换到硬盘*/
VmHWM: 18020 kB /*文件内存映射和匿名内存映射的大小*/
VmRSS: 18020 kB /*应用程序正在使用的物理内存的大小,就是用ps命令的参数rss的值 (rss)*/
VmData: 12240 kB /*程序数据段的大小(所占虚拟内存的大小),存放初始化了的数据*/
VmStk: 84 kB /*进程在用户态的栈的大小*/
VmExe: 576 kB /*程序所拥有的可执行虚拟内存的大小,代码段,不包括任务使用的库 */
VmLib: 21072 kB /*被映像到任务的虚拟内存空间的库的大小*/
VmPTE: 56 kB /*该进程的所有页表的大小*/
Threads: 1 /*共享使用该信号描述符的任务的个数*/
JVM 内存分配
java内存组成介绍:堆(Heap)和非堆(Non-heap)内存
按照官方的说法:“Java 虚拟机具有一个堆,堆是运行时数据区域,所有类实例和数组的内存均从此处分配。堆是在 Java 虚拟机启动时创建的。”“在JVM中堆之外的内存称为非堆内存(Non-heap memory)”。可以看出JVM主要管理两种类型的内存:堆和非堆。简单来说堆就是Java代码可及的内存,是留给开发人员使用的;非堆就是JVM留给 自己用的,所以方法区、JVM内部处理或优化所需的内存(如JIT编译后的代码缓存)、每个类结构(如运行时常数池、字段和方法数据)以及方法和构造方法 的代码都在非堆内存中。

- JVM本身需要的内存,包括其加载的第三方库以及这些库分配的内存
- NIO的DirectBuffer是分配的native memory
- 内存映射文件,包括JVM加载的一些JAR和第三方库,以及程序内部用到的。上面 pmap 输出的内容里,有一些静态文件所占用的大小不在Java的heap里,因此作为一个Web服务器,赶紧把静态文件从这个Web服务器中人移开吧,放到nginx或者CDN里去吧。
- JIT, JVM会将Class编译成native代码,这些内存也不会少,如果使用了Spring的AOP,CGLIB会生成更多的类,JIT的内存开销也会随之变大,而且Class本身JVM的GC会将其放到Perm Generation里去,很难被回收掉,面对这种情况,应该让JVM使用ConcurrentMarkSweep GC,并启用这个GC的相关参数允许将不使用的class从Perm Generation中移除, 参数配置: -XX:+UseConcMarkSweepGC -X:+CMSPermGenSweepingEnabled -X:+CMSClassUnloadingEnabled,如果不需要移除而Perm Generation空间不够,可以加大一点: -X:PermSize=256M -X:MaxPermSize=512M
- JNI,一些JNI接口调用的native库也会分配一些内存,如果遇到JNI库的内存泄露,可以使用valgrind等内存泄露工具来检测
- 线程栈,每个线程都会有自己的栈空间,如果线程一多,这个的开销就很明显了
- jmap/jstack 采样,频繁的采样也会增加内存占用,如果你有服务器健康监控,记得这个频率别太高,否则健康监控变成致病监控了。
方法区
也称”永久代” 、“非堆”,它用于存储虚拟机加载的类信息、常量、静态变量、是各个线程共享的内存区域。默认最小值为16MB,最大值为64MB,可以通过-XX:PermSize 和 -XX:MaxPermSize 参数限制方法区的大小。
运行时常量池:是方法区的一部分,Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池,用于存放编译器生成的各种符号引用,这部分内容将在类加载后放到方法区的运行时常量池中。
虚拟机栈
描述的是java 方法执行的内存模型:每个方法被执行的时候 都会创建一个“栈帧”用于存储局部变量表(包括参数)、操作栈、方法出口等信息。每个方法被调用到执行完的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。声明周期与线程相同,是线程私有的。
局部变量表存放了编译器可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(引用指针,并非对象本身),其中64位长度的long和double类型的数据会占用2个局部变量的空间,其余数据类型只占1个。局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在栈帧中分配多大的局部变量是完全确定的,在运行期间栈帧不会改变局部变量表的大小空间。
本地方法栈
与虚拟机栈基本类似,区别在于虚拟机栈为虚拟机执行的java方法服务,而本地方法栈则是为Native方法服务。
堆
也叫做java 堆、GC堆是java虚拟机所管理的内存中最大的一块内存区域,也是被各个线程共享的内存区域,在JVM启动时创建。该内存区域存放了对象实例及数组(所有new的对象)。其大小通过-Xms(最小值)和-Xmx(最大值)参数设置,-Xms为JVM启动时申请的最小内存,默认为操作系统物理内存的1/64但小于1G,-Xmx为JVM可申请的最大内存,默认为物理内存的1/4但小于1G,默认当空余堆内存小于40%时,JVM会增大Heap到-Xmx指定的大小,可通过-XX:MinHeapFreeRation=来指定这个比列;当空余堆内存大于70%时,JVM会减小heap的大小到-Xms指定的大小,可通过XX:MaxHeapFreeRation=来指定这个比列,对于运行系统,为避免在运行时频繁调整Heap的大小,通常-Xms与-Xmx的值设成一样。
由于现在收集器都是采用分代收集算法,堆被划分为新生代和老年代。新生代主要存储新创建的对象和尚未进入老年代的对象。老年代存储经过多次新生代GC(Minor GC)任然存活的对象。
程序计数器
是最小的一块内存区域,它的作用是当前线程所执行的字节码的行号指示器,在虚拟机的模型里,字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、异常处理、线程恢复等基础功能都需要依赖计数器完成。
直接内存
直接内存并不是虚拟机内存的一部分,也不是Java虚拟机规范中定义的内存区域。jdk1.4中新加入的NIO,引入了通道与缓冲区的IO方式,它可以调用Native方法直接分配堆外内存,这个堆外内存就是本机内存,不会影响到堆内存的大小。
JVM 内存分析
查看 JVM 堆内存情况
jmap -heap [pid]
1 | [root@server ~]$ jmap -heap 837 |
关于这里的几个generation网上资料一大把就不细说了,这里算一下求和可以得知前者总共给Java环境分配了644M的内存,而ps输出的VSZ和RSS分别是7.4G和2.9G,这到底是怎么回事呢?
前面jmap输出的内容里,MaxHeapSize 是在命令行上配的,-Xmx4096m,这个java程序可以用到的最大堆内存。
VSZ是指已分配的线性空间大小,这个大小通常并不等于程序实际用到的内存大小,产生这个的可能性很多,比如内存映射,共享的动态库,或者向系统申请了更多的堆,都会扩展线性空间大小,要查看一个进程有哪些内存映射,可以使用 pmap 命令来查看:
pmap -x [pid]1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16[root@server ~]$ pmap -x 837
837: java
Address Kbytes RSS Dirty Mode Mapping
0000000040000000 36 4 0 r-x-- java
0000000040108000 8 8 8 rwx-- java
00000000418c9000 13676 13676 13676 rwx-- [ anon ]
00000006fae00000 83968 83968 83968 rwx-- [ anon ]
0000000700000000 527168 451636 451636 rwx-- [ anon ]
00000007202d0000 127040 0 0 ----- [ anon ]
...
...
00007f55ee124000 4 4 0 r-xs- az.png
00007fff017ff000 4 4 0 r-x-- [ anon ]
ffffffffff600000 4 0 0 r-x-- [ anon ]
---------------- ------ ------ ------
total kB 7796020 3037264 3023928
这里可以看到很多anon,这些表示这块内存是由mmap分配的。
RSZ是Resident Set Size,常驻内存大小,即进程实际占用的物理内存大小, 在现在这个例子当中,RSZ和实际堆内存占用差了2.3G,这2.3G的内存组成分别为:
查看 JVM 堆各个分区的内存情况
jstat -gcutil [pid]1
2
3
4[root@server ~]$ jstat -gcutil 837 1000 20
S0 S1 E O P YGC YGCT FGC FGCT GCT
0.00 80.43 24.62 87.44 98.29 7101 119.652 40 19.719 139.371
0.00 80.43 33.14 87.44 98.29 7101 119.652 40 19.719 139.371
分析 JVM 堆内存中的对象
查看存活的对象统计
jmap -histo:live [pid]
dump 内存
jmap -dump:format=b,file=heapDump [pid]
然后用jhat命令可以参看
jhat -port 5000 heapDump
在浏览器中访问:http://localhost:5000/ 查看详细信息
服务指标
响应时间(RT)
响应时间是指系统对请求作出响应的时间。直观上看,这个指标与人对软件性能的主观感受是非常一致的,因为它完整地记录了整个计算机系统处理请求的时间。由于一个系统通常会提供许多功能,而不同功能的处理逻辑也千差万别,因而不同功能的响应时间也不尽相同,甚至同一功能在不同输入数据的情况下响应时间也不相同。所以,在讨论一个系统的响应时间时,人们通常是指该系统所有功能的平均时间或者所有功能的最大响应时间。当然,往往也需要对每个或每组功能讨论其平均响应时间和最大响应时间。
对于单机的没有并发操作的应用系统而言,人们普遍认为响应时间是一个合理且准确的性能指标。需要指出的是,响应时间的绝对值并不能直接反映软件的性能的高低,软件性能的高低实际上取决于用户对该响应时间的接受程度。对于一个游戏软件来说,响应时间小于100毫秒应该是不错的,响应时间在1秒左右可能属于勉强可以接受,如果响应时间达到3秒就完全难以接受了。而对于编译系统来说,完整编译一个较大规模软件的源代码可能需要几十分钟甚至更长时间,但这些响应时间对于用户来说都是可以接受的。
吞吐量(Throughput)
吞吐量是指系统在单位时间内处理请求的数量。对于无并发的应用系统而言,吞吐量与响应时间成严格的反比关系,实际上此时吞吐量就是响应时间的倒数。前面已经说过,对于单用户的系统,响应时间(或者系统响应时间和应用延迟时间)可以很好地度量系统的性能,但对于并发系统,通常需要用吞吐量作为性能指标。
对于一个多用户的系统,如果只有一个用户使用时系统的平均响应时间是t,当有你n个用户使用时,每个用户看到的响应时间通常并不是n×t,而往往比n×t小很多(当然,在某些特殊情况下也可能比n×t大,甚至大很多)。这是因为处理每个请求需要用到很多资源,由于每个请求的处理过程中有许多不走难以并发执行,这导致在具体的一个时间点,所占资源往往并不多。也就是说在处理单个请求时,在每个时间点都可能有许多资源被闲置,当处理多个请求时,如果资源配置合理,每个用户看到的平均响应时间并不随用户数的增加而线性增加。实际上,不同系统的平均响应时间随用户数增加而增长的速度也不大相同,这也是采用吞吐量来度量并发系统的性能的主要原因。一般而言,吞吐量是一个比较通用的指标,两个具有不同用户数和用户使用模式的系统,如果其最大吞吐量基本一致,则可以判断两个系统的处理能力基本一致。
并发用户数
并发用户数是指系统可以同时承载的正常使用系统功能的用户的数量。与吞吐量相比,并发用户数是一个更直观但也更笼统的性能指标。实际上,并发用户数是一个非常不准确的指标,因为用户不同的使用模式会导致不同用户在单位时间发出不同数量的请求。一网站系统为例,假设用户只有注册后才能使用,但注册用户并不是每时每刻都在使用该网站,因此具体一个时刻只有部分注册用户同时在线,在线用户就在浏览网站时会花很多时间阅读网站上的信息,因而具体一个时刻只有部分在线用户同时向系统发出请求。这样,对于网站系统我们会有三个关于用户数的统计数字:注册用户数、在线用户数和同时发请求用户数。由于注册用户可能长时间不登陆网站,使用注册用户数作为性能指标会造成很大的误差。而在线用户数和同事发请求用户数都可以作为性能指标。相比而言,以在线用户作为性能指标更直观些,而以同时发请求用户数作为性能指标更准确些。
QPS每秒查询率(Query Per Second)
每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准,在因特网上,作为域名系统服务器的机器的性能经常用每秒查询率来衡量。对应fetches/sec,即每秒的响应请求数,也即是最大吞吐能力。
从以上概念来看吞吐量和响应时间是衡量系统性能的重要指标,QPS虽然和吞吐量的计量单位不同,但应该是成正比的,任何一个指标都可以含量服务器的并行处理能力。当然Throughput更关心数据量,QPS更关心处理笔数。
CPU利用率
CPU Load Average < CPU个数 核数 0.7
Context Switch Rate
就是Process(Thread)的切换,如果切换过多,会让CPU忙于切换,也会导致影响吞吐量。《高性能服务器架构 》这篇文章的第2节就是说的是这个问题的。究竟多少算合适?google了一大圈,没有一个确切的解释。Context Switch大体上由两个部分组成:中断和进程(包括线程)切换,一次中断(Interrupt)会引起一次切换,进程(线程)的创建、激活之类的也会引起一次切换。CS的值也和TPS(Transaction Per Second)相关的,假设每次调用会引起N次CS,那么就可以得出
Context Switch Rate = Interrupt Rate + TPS* N
CSR减掉IR,就是进程/线程的切换,假如主进程收到请求交给线程处理,线程处理完毕归还给主进程,这里就是2次切换。也可以用CSR、IR、TPS的值代入公式中,得出每次事物导致的切换数。因此,要降低CSR,就必须在每个TPS引起的切换上下功夫,只有N这个值降下去,CSR就能降低,理想情况下N=0,但是无论如何如果N >= 4,则要好好检查检查。另外网上说的CSR<5000,我认为标准不该如此单一。
这三个指标在 LoadRunner 中可以监控到;另外,在 linux 中,也可以用 vmstat 查看r(Load Arerage),in(Interrupt)和cs(Context Switch)
工具
uptime
dmesg
top
查看进程活动状态以及一些系统状况
vmstat
查看系统状态、硬件和系统信息等
iostat
查看CPU 负载,硬盘状况
sar
综合工具,查看系统状况
mpstat
查看多处理器状况
netstat
查看网络状况
iptraf
实时网络状况监测
tcpdump
抓取网络数据包,详细分析
mpstat
查看多处理器状况
tcptrace
数据包分析工具
netperf
网络带宽工具
dstat
综合工具,综合了 vmstat, iostat, ifstat, netstat 等多个信息
Reference
>
https://tmq.qq.com/2016/07/it-is-necessary-to-know-the-background-performance-test/
https://www.ibm.com/developerworks/java/library/j-nativememory-linux/
https://www.oracle.com/technetwork/java/javase/index-137495.html
https://www.hollischuang.com/archives/303
