HBase 简介
HBase是Apache Hadoop的数据库,基于列存储、构建在HDFS上的分布式存储系统,能够对大型数据提供随机、实时的读写访问,是Google的BigTable的开源实现。HBase的目标是存储并处理大型的数据,仅用普通的硬件配置,就能够处理海量数据。
HBase 的优点
- 高可扩展性
HBase 是真正意义上的线性水平扩展。数据量累计到一定程度(可配置),HBase系统会自动对数据进行水平切分,并分配不同的服务器来管理这些数据。这些数据可以被扩散到上千个普通服务器上。这样一方面可以由大量普通服务器组成大规模集群,来存放海量数据(从几个 TB 到几十 PB 的数据)。另一方面,当数据峰值接近系统设计容量时,可以简单通过增加服务器的方式来扩大容量。这个动态扩容过程无需停机,HBase系统可以照常运行并提供读写服务,完全实现动态无缝无宕机扩容。 - 高性能
HBase 的设计目的之一是支持高并发用户数的高速读写访问。这是通过两方面来实现的。首先数据行被水平切分并分布到多台服务器上,在大量用户访问时,访问请求也被分散到了不同的服务器上,虽然每个服务器的服务能力有限,但是数千台服务器汇总后可以提供极高性能的访问能力。其次,HBase 设计了高效的缓存机制,有效提高了访问的命中率,提高了访问性能。 - 高可用性
HBase 建立在 HDFS 之上。HDFS 提供了数据自动复制和容错的功能。HBase 的日志和数据都存放在 HDFS 上,即使在读写过程中当前服务器出现故障(硬盘、内存、网络等故障),日志也不会丢失,数据都可以从日志中自动恢复。HBase 系统会自动分配其他服务器接管并恢复这些数据。因此一旦成功写入数据,这些数据就保证被持久化并被冗余复制,整个系统的高可用性得到保证。
数据模型
表
- 数据量:一张表可以有数十亿行,上百万列。
- 最大版本数:通常是3,如果对于更新比较频繁的应用完全可以设置为1,能够快速的淘汰无用数据,对于节省存储空间和提高查询速度有效果。不过这类需求在海量数据领域比较小众。
- 压缩算法:可以尝试一下最新出炉的snappy算法,相对lzo来说,压缩率接近,压缩效率稍高,解压效率高很多。
- inmemory:表在内存中存放,一直会被忽略的属性。如果完全将数据存放在内存中,那么hbase和现在流行的内存数据库memorycached和redis性能差距有多少,尚待实测。
- bloomfilter:根据应用来定,看需要精确到rowkey还是column。不过这里需要理解一下原理,bloomfilter的作用是对一个region下查找记录所在的hfile有用。即如果一个region下的hfile数量很多,bloomfilter的作用越明显。适合那种compaction赶不上flush速度的应用。
无模式
每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一张表中不同的行可以有截然不同的列;- 面向列
面向列(族)的存储和权限控制,列(族)独立检索; - 稀疏
对于空(null)的列,并不占用存储空间,表可以设计的非常稀疏; - 数据多版本
每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时的时间戳; - 数据类型单一
HBase中的数据都是字符串,没有类型。 - 存储单元 Cell
由{rowkey, colomnFamily:colomnQualifier, version} 确定的唯一单元,存储的数据是byte[]类型的。
HBase 的设计与实现
HBase 的架构
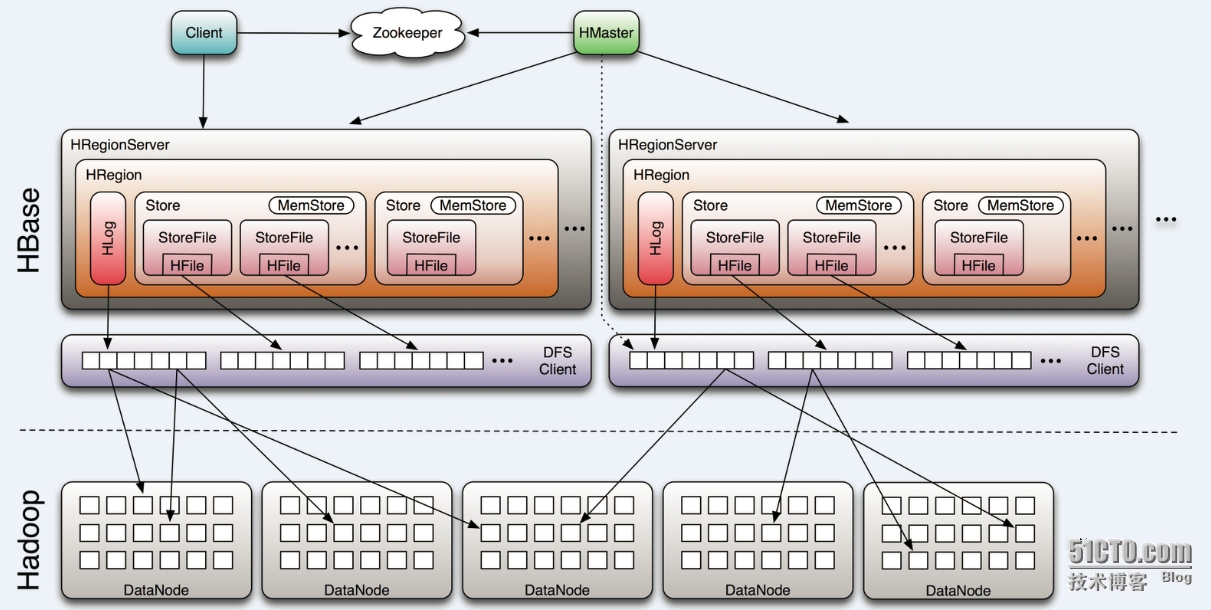
由上图可知,hbase包括Clinet、HMaster、HRegionServer、ZooKeeper组件
各组件功能介绍:
- Client
Client主要通过ZooKeeper与Hbaser和HRegionServer通信,对于管理操作:client向master发起请求,对于数据读写操作:client向regionserver发起请求 - ZooKeeper
zk负责存储_root_表的地址,也负责存储当前服务的master地址,regsion server也会将自身的信息注册到zk中,以便master能够感知region server的状态,zk也会协调active master,也就是可以提供一个选举master leader,也会协调各个region server的容灾流程 - HMaster
master可以启动多个master,master主要负责table和region的管理工作,响应用户对表的CRUD操作,管理region server的负载均衡,调整region 的分布和分配,当region server停机后,负责对失效的regionn进行迁移操作 - HRegionServer
region server主要负责响应用户的IO请求,并把IO请求转换为读写HDFS的操作
HBase 的架构详解
https://www.mapr.com/blog/in-depth-look-hbase-architecture#.VdMxvWSqqko
HBase, Mysql 的比较
Mysql 是关系型数据库,对于数据量不大(百万级别),强依赖事务的业务,使用Mysql。
HBase 适用于对大数据进行随机、实时访问的场合,支持海量数据,扩展性好。
HBase 不适用的场景:
- 对分布式事务支持的不好
- 不支持多表的联合查询
- 对于复杂查询,需要扫描全表,且不支持索引
设计 HBase 表
RowKey 的设计
Rowkey唯一原则,必须在设计上保证其唯一性。但是还有几点需要注意的地方:
RowKey 长度的设计
Rowkey是一个二进制码流,可以是任意字符串,最大长度64KB,实际应用中一般为10~100bytes,存为byte[]字节数组。
- 定长
定长的好处是 RowKey 排序时是按字典序且不受不同长度的影响 - 短
不要超过16个字节。- 数据的持久化文件 HFile 是按照 KeyValue 存储的,如果 Rowkey 过长比如100个字节,1000万列数据光 Rowkey 就要占用100*1000万=10亿个字节,将近1G数据,这会极大影响 HFile 的存储效率;
- MemStore 将缓存部分数据到内存,如果 Rowkey 字段过长内存的有效利用率会降低,系统将无法缓存更多的数据,这会降低检索效率。
- 16个字节
目前操作系统是都是64位系统,内存8字节对齐。控制在16个字节,8字节的整数倍利用操作系统的最佳特性。
RowKey 含义的设计
RowKey 虽然是越短越好,但也需要考虑 RowKey 的含义。由于 HBase 是按字典序存储,所以 RowKey 设计的合理可以提高查询效率(因为这会提高 RegionServer 的缓存命中率),并且有意义的 RowKey 也便于在 scan 表的时候确定 startRow 和 stopRow。
- RowKey 包含时间
不要将时间放在二进制码的前面,建议将 RowKey 的高位作为散列字段(或者本身就已经是散列的其他id,例如userId),低位放时间字段。否则最新的数据都集中放在某个 RegionServer,而访问量又都集中在最新的数据上,将会导致 Hotspotting 现象,降低了访问速度,同时也增加了 RegionServer Crash 的概率。
但考虑到是按字典序存储,如果想让最新的数据在最前面,可以使用 Long.MAX_VALUE – timestamp 作为 RowKey 的一部分。 - RowKey 包含多个含义时
各个含义用某种分隔符分开,比如包含用户,类型,时间三种含义的 RowKey, 可以设计为 userId#type#timestamp,这样如果需要查找某个用户某段时间的数据,scan 时只需要根据 userId 设置 startRow 和 stopRow 即可。
RowKey 性能的设计
RowKey 是按照字典序存储,利用这个排序特点,将经常一起读取或者最近可能被访问到的数据存储到一块可以提高查询效率。
- Hotspotting
It is always advisable not to use sequential row keys, even though you get better scan results. More info here.
Salting Row Key. To prevent hot spotting on writes, the row key may be “salted” by inserting a leading byte into the row key which is a mod over N buckets of the hash of the entire row key. This ensures even distribution of writes when the row key is a monotonically increasing value (often a timestamp representing the current time). - Length of row key
For each cell, rowkey details, column family, and qualifier details are stored. So it is always advisable to keep them as shot as possible, mainly because the same information is repeated on large scale. - So whats next
salt usage and its prefixing will help to distribute the rows among region servers.This can help you.
ColumnFamily 的设计
ColumnFamily 的长度
The column family and column qualifier names are repeated for each row. Therefore, keep the names as short as possible to reduce the amount of data that HBase stores and reads. For example, use f:q instead of mycolumnfamily:mycolumnqualifier.
ColumnFamily 的数量
On the number of column families
HBase currently does not do well with anything above two or three column families so keep the number of column families in your schema low. Currently, flushing and compactions are done on a per Region basis so if one column family is carrying the bulk of the data bringing on flushes, the adjacent families will also be flushed though the amount of data they carry is small. When many column families the flushing and compaction interaction can make for a bunch of needless i/o loading (To be addressed by changing flushing and compaction to work on a per column family basis). For more information on compactions, see compaction. (具体的细节见第2节)
Try to make do with one column family if you can in your schemas. Only introduce a second and third column family in the case where data access is usually column scoped; i.e. you query one column family or the other but usually not both at the one time.
Where multiple ColumnFamilies exist in a single table, be aware of the cardinality (i.e., number of rows). If ColumnFamilyA has 1 million rows and ColumnFamilyB has 1 billion rows, ColumnFamilyA’s data will likely be spread across many, many regions (and RegionServers). This makes mass scans for ColumnFamilyA less efficient.
建议HBASE列族的数量设置的越少越好。由于HBASE的FLUSHING和压缩是基于REGION的当一个列族所存储的数据达到FLUSHING阀值时,该表的所有列族将同时进行FLASHING操作,这将带来不必要的I/O开销。同时还要考虑到同一个表中不同列族所存储的记录数量的差别,即列族的势。当列族数量差别过大将会使包含记录数量较少的列族的数据分散在多个Region之上,而Region可能是分布是不同的RegionServer上。这样当进行查询等操作系统的效率会受到一定影响。
Column 的设计
Column 的长度
The column family and column qualifier names are repeated for each row. Therefore, keep the names as short as possible to reduce the amount of data that HBase stores and reads. For example, use f:q instead of mycolumnfamily:mycolumnqualifier.
Column 的数量
Column mapping: one to many
You can map a single HBase entity (row key or a column) to multiple SQL columns. This kind of mapping is called one to many. HBase stores a lot of information for each value. If you stored each SQL column individually, the required storage space would be very large. For the best performance, put columns that are queried together into a single dense HBase column to help reduce the data that is fetched from HBase. A dense column is a single HBase column that maps to multiple SQL columns.
For example, if table T1 has nine columns with 1.5 million rows. and you use a one-to-one mapping, this table requires 522 MB of storage. However, if table T1 uses a one-to-many mapping, the table requires only 276 MB of storage.
读 HBase 的性能
HBase Pool
Use pool of workers to parallel requests. You may find useful HTablePool class for managing connections in workers.
批量读
通过调用 HTable.get(Get) 方法可以根据一个指定的 RowKey 获取一行记录,同样 HBase 提供了另一个方法:通过调用 HTable.get(List
Scan
- Scanner Caching
hbase.client.scanner.caching配置项可以设置HBase scanner一次从服务端抓取的数据条数,默认情况下一次一条。通过将其设置成一个合理的值,可以减少scan过程中next()的时间开销,代价是 scanner需要通过客户端的内存来维持这些被cache的行记录。 - Scan AttributeSelection
scan时指定需要的Column Family,可以减少网络传输数据量,否则默认scan操作会返回整行所有Column Family的数据。 - Close ResultScanner
通过scan取完数据后,记得要关闭ResultScanner,否则RegionServer可能会出现问题(对应的Server资源无法释放)。
PrefixFilter
PefixFilter Vs Scan
- HBase filters - even row filters - are really slow, since in most cases these do a complete table scan, and then filter on those results.
- Row key range scans however, are indeed much faster - they do the equivalent of a filtered table scan. This is because the row keys are stored in sorted order (this is one of the basic guarantees of HBase, which is a BigTable-like solution), so the range scans on row keys are very fast.
Convert PrefixFilter to Scan
PrefixFilter: abc
Scan ‘mytable’, {STARTROW => ‘abc’, ENDROW => ‘abd’}
如何解决事务
- transactions over hbase
The way HBase works is that locks are held in the regionserver (not in the client) when the Puts are applied to make sure that rows are written in an atomic block but it does not provide snapshot isolation (you need to use something like omid if you want that).
Since HBase does not guarantee any consistency between regions (and each region is hosted at exactly one RegionServer) all MVCC data structures only need to be kept in memory on every region server.
I would probably not use HBase for a use case like this. but if you must you can lock the row, read, update if needed - read more about lock and some of its problems here ngdata.com/hbase-row-locks . Again, I’d try to rethink the scenario for instance, HBase support multiple version so you can update anyway and sort things later (e.g. in a coprocessor that runs after update)
RowLock and associated operations are deprecated in 0.94 and removed in 0.96.issues.apache.org/jira/browse/HBASE-7315 – Matt Ball
- hbase checkAndPut
hbase checkandput performance
When you use checkAndPut() you do one RPC-call per request. So, you can’t achieve performance more then 1 / rtt requests per second (rtt is Round Trip Time). If you have rtt 1ms between your client and region server, your theoretical maximum is 1000 rps. When using batch operations like put(List) you need a lot less RPC-calls causing performance increase.
Reference
http://blog.linezing.com/2012/03/hbase-performance-optimization/
https://www.ibm.com/support/knowledgecenter/SSPT3X_2.1.2/com.ibm.swg.im.infosphere.biginsights.analyze.doc/doc/bigsql_designhints.html
http://blog.kissdata.com/2014/07/30/hbase-scheme-tips.html
http://blog.chedushi.com/archives/9720
https://www.mapr.com/blog/in-depth-look-hbase-architecture#.VdMxvWSqqko
https://cloud.google.com/bigtable/docs/schema-design
http://www.slideshare.net/alexbaranau/transactions-over-hbase
https://hbase.apache.org/acid-semantics.html
